Optimierung
Das [!Gebiet] der Optimierung in der angewandten Mathematik beschäftigt sich damit, optimale Parameter eines - meist komplexen - Systems zu finden. "Optimal" bedeutet, dass eine Zielfunktion minimiert oder maximiert wird. Optimierungsprobleme stellen sich in der Wirtschaftsmathematik, Statistik, Operations Research und generell in allen wissenschaftlichen Disziplinen, in denen mit unbekannten Parametern gearbeitet wird wie beispielsweise in der Physik, Chemie und Meteorologie.
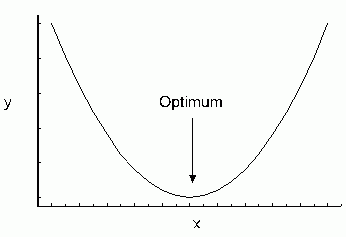
Beispiel einer lokalen Optimierungsaufgabe
Beispiel eines einfachen Optimierungsproblems
Das einfachste Optimierungsproblem ist das Auffinden eines Minimums oder Maximums einer analytischen eindimensionalen Funktion , was in der Regel durch Auffinden der Nullstellen der ersten Ableitung gelingt.
Beispiele für Optimierungsprobleme
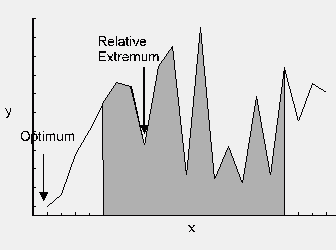
- Wirtschaftsmathematik: Die Zielfunktion stellt hier meist der Gewinn oder der Umsatz einer Firma dar, Parameter sind Rohstoffe, Personal-, Maschineneinsatz, Preise usw. Die Zielfunktion soll maximiert werden. Im Grunde genommen handelt es sich um eine vereinfachte Formalisierung eines grundlegenden Managementproblems. Seine systematische Fundierung erhält es in der Operations Research.
- Statistik, Data-Mining: Statistische Modelle enthalten offene Parameter, die geschätzt werden. Ein Parametersatz ist optimal, wenn die zugehörige Modellinstanz die Datenbeziehungen optimal darstellt, d. h. die Abweichungen der modellierten Daten (im Sinne einer passenden Gütefunktion) von den empirischen Daten so gering wie möglich, also optimal sind. Die Zielfunktion kann hier unterschiedlich gewählt werden, zum Beispiel als Least Square oder als Likelihood-Funktion.
- Klimaforschung: Klimamodelle stellen vereinfachte numerische Systeme der eigentlichen hydrodynamischen Prozesse in der Atmosphäre dar. Innerhalb der Gitterzellen müssen die Wechselwirkungen durch Gleichungen approximiert werden. Die Gleichungen können dabei entweder aus grundlegenden hydrodynamischen Gesetzen abgeleitet werden oder es werden empirische Gleichungen verwendet, also im Grunde statistische Modelle, deren Parameter so optimiert werden müssen, dass die Klimamodelle die tatsächlichen Prozesse möglichst gut darstellen.
- Spieltheorie: Erreicht eine Spielerpopulation in einem Superspiel ein Populationsoptimum? Oder wenigstens ein Pareto-Optimum? Ist dieses Gleichgewicht stabil?
- Physik: Auswertung von Messkurven, indem Parameterwerte einer Theoriefunktion so variiert werden ("Optimierung im Parameterraum", s. a. Ausgleichsrechnung ("Fitten")), dass die Theoriefunktion bestmöglich mit der Messkurve übereinstimmt.
Abgrenzung
Verwandt zur Optimierung ist das [!Gebiet] der Approximation in der Numerik. Man kann umgekehrt sagen: Ein Approximationsproblem ist das Problem, den Abstand (die Metrik) zweier Funktionen zu minimieren.
Begriffe: Zielfunktion, Nebenbedingungen, zulässige Menge, lokale und globale Optimierung
Es sei im Folgenden eine Minimierungsaufgabe angenommen. Das, was minimiert werden soll, zum Beispiel ein Abstand, nennt man Zielfunktion. Das, was variiert wird, sind die Parameter oder Variablen der Zielfunktion. Bei einer zweidimensionalen Optimierungsaufgabe (also zwei unabhängige Parameter) kann man sich die Zielfunktion räumlich vorstellen, indem die Parameter die Längen- und Tiefenachse aufspannen. Die Höhe ist dann der Zielfunktionswert. Im Allgemeinen entsteht so ein "Gebirge" mit Bergen und Tälern.
Falls es sich bei der Optimierungsaufgabe tatsächlich um ein Approximationsproblem handelt, dann spricht man bei dem "Gebirge" mitunter auch von der Fittopologie. In diesem Fall wird als Zielfunktion in den allermeisten Fällen die Fehlerquadratsumme eingesetzt (siehe Methode der kleinsten Quadrate).
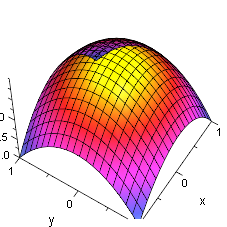
Nach unten geöffnete Parabel
Da die Zielfunktion ein "Gebirge" darstellt, ist das Optimierungsproblem damit gleichzusetzen, in diesem Gebirge das tiefste Tal (Minimierung) oder den höchsten Gipfel (Maximum) zu finden. Der Aufwand zur Lösung der Aufgabe hängt entscheidend von der Form des "Gebirges" ab. Extrembeispiel für eine Minimierungsaufgabe wäre die Form eine Billardtisches, also einer absolut flachen Ebene, aus dem an zufälligen Punkten einzelne nadelförmige Spitzen herausragen. In diesem Fall hilft keinerlei Suchalgorithmus, man kann nur zufällig suchen (Monte-Carlo-Methode) oder systematisch die gesamte Fläche abrastern. Der einfachste Fall einer zweidimensionalen Optimierierungsaufgabe wäre es, wenn das Gebirge die Form einer (nach unten geöffneten) um die Höhenachse rotierten Parabel hätte, dessen Spitze man finden müsste. Besteht die Optimierungsaufgabe darin, von einem gegebenen Punkt im Gebirge aus das nächste relative (lokale) Minimum oder Maximum in der Nachbarschaft zu finden, dann spricht man von lokaler Optimierung. Besteht die Aufgabe darin, das absolute Minimum oder Maximum im gesamten Gebirge zu finden, dann spricht man von globaler Optimierung. Die beiden Aufgaben haben einen stark unterschiedlichen Schwierigkeitsgrad: Für die lokale Optimierung gibt es zahlreiche Methoden, die alle mehr oder weniger schnell in allen nicht allzuschwierigen Fällen mit großer Sicherheit zum Ziel führen. Bei der globalen Optimierung hängt die Lösbarkeit der Aufgabe im Rahmen eines gegebenen oder realisierbaren Rechenbudgets sehr stark von der Zielfunktionstopologie ab.
Häufig ist man nur an solchen Werten für die Parameter interessiert, die zusätzliche Nebenbedingungen erfüllen. Diese Nebenbedingungen können in Form von Gleichungen oder Ungleichungen beschrieben sein, oder explizit eine Menge beschreiben (zum Beispiel nur ganzzahlige Lösungen). Die Menge aller Parameterwerte, die die Nebenbedingungen erfüllen, bezeichnet man als zulässige Menge.
Klassifikation
Skalare Optimierungsprobleme
Ein skalares Optimierungsproblem lässt sich mathematisch als
- "Minimiere/maximiere unter der Nebenbedingung "
darstellen; hierbei ist eine reellwertige Funktion und . Häufig ist die zulässige Menge indirekt durch eine Funktion gegeben, gewöhnlich standardisiert in der Form
- mit einer vektorwertigen Funktion .
Je nach Form von lassen sich skalare Optimierungsprobleme wie folgt klassifizieren:
- Variationsproblem: ist unendlichdimensional, speziell ein Funktionenraum.
- Optimales Steuerungsproblem: Klassisches Variationsproblem mit Differentialgleichungsnebenbedingung
- Lineares Programm: wobei ist affin, ist linear.
- Quadratisches Programm: wie oben, nur ist eine quadratische Funktion.
- Nichtlineares Programm: sind beliebige Funktionen (meist stetig, differenzierbar angenommen; in der engeren Umgebung eines Optimums kann oft eine quadratische Näherung verwendet werden, was zu einigen der praktischen Verfahren führt.)
- Ganzzahliges Programm (auch diskretes Programm): Zusätzlich sind die zulässigen x auf ganzzahlige (oder allgemeiner diskrete Werte) [!beschränkt].
- Stochastisches Programm: Einige Parameter in der Beschreibung von sind unbekannt (aber ihre Zufallsverteilung ist bekannt).
- Konvexes Programm: ist konvex und ist konvex (konkav) falls minimiert (maximiert) wird.
Jedes dieser Teilgebiete der Optimierung hat speziell darauf abgestimmte Lösungsverfahren.
Hinweis zur Terminologie: "Programm" ist als Synonym zu "Optimierungsproblem" zu verstehen (und nicht als "Computerprogramm"). Die Verwendung des Begriffes "Programm" ist historisch begründet: Die ersten Anwendungen der Optimierung waren militärische Probleme, bei denen ein Aktionsplan (engl: program of actions) zu finden war.
Vektoroptimierungsprobleme
Ein Optimierungsproblem aus der Vektoroptimierung (auch Pareto-Optimierung genannt) ist dagegen ein Problem, bei dem die Werte mehrerer Zielfunktionen gleichzeitig zu optimieren sind. Dies lässt sich formalisieren, indem eine vektorwertige Zielfunktion optimiert wird. Lösungen, die alle Komponenten der Zielfunktion gleichzeitig zu einem Optimum führen, sind in der Regel nicht vorhanden; vielmehr ergibt sich im Allgemeinen eine größere Lösungsmenge, aus der zum Beispiel durch eine Skalarisierung (Gewichtung der Einzelkomponenten der Zielfunktion) ein einzelner Optimalpunkt selektiert werden kann.
Lineare und ganzzahlige Optimierung
Ein wichtiger Spezialfall ist die lineare Optimierung. Hierbei ist die Zielfunktion linear, und die Nebenbedingungen sind durch ein System linearer Gleichungen und Ungleichungen darstellbar. Jedes lokale Optimum ist automatisch auch globales Optimum, da der zulässige Bereich konvex ist. Es gibt Methoden, um das globale Optimum im Prinzip exakt zu berechnen, wovon die bekannteste das Simplex-Verfahren ist (nicht zu verwechseln mit dem Downhill-Simplex-Verfahren weiter unten). Seit den 1990er Jahren gibt es allerdings auch effiziente Innere-Punkte-Verfahren, die bei bestimmten Arten von Optimierungsproblemen konkurrenzfähig zum Simplex-Verfahren sein können.
Eine Beschränkung auf ganzzahlige Variablen macht das Problem deutlich schwerer, erweitert aber gleichzeitig die Anwendungsmöglichkeiten. Diese sogenannte ganzzahlige lineare Optimierung wird beispielsweise in der Produktionsplanung, im Scheduling, in der Tourenplanung oder in der Planung von Telekommunikations- oder Verkehrsnetzen eingesetzt.
Methoden der lokalen nichtlinearen Optimierung ohne Nebenbedingungen
Schwieriger als die lineare Optimierung ist der Fall der nichtlinearen Optimierung, bei der die Zielfunktion, die Nebenbedingungen oder sogar beide nichtlinear sind. Bei der lokalen Optimierung hängt die Wahl der Methode von der genauen Problemstellung ab: Handelt es sich um eine beliebig exakt bestimmte Zielfunktion? (Das ist bei stochastischen Zielfunktionen oft nicht der Fall) Ist die Zielfunktion in der Umgebung streng monoton, nur monoton oder könnte es "unterwegs" sogar kleine relative Extrema geben? Wie hoch sind die Kosten, einen Gradienten zu bestimmen?
Beispiele für Methoden:
Ableitungsfreie Methoden
- Intervallhalbierungsverfahren, goldener Schnitt und andere Verfahren der Liniensuche.
- Sekantenverfahren
- Downhill-Simplex-Verfahren
Diese Methoden kosten viele Iterationen, sind aber (teilweise) relativ robust gegenüber Problemen in der Zielfunktion, zum Beispiel kleine relative Extrema und sie verlangen nicht die Berechnung eines Gradienten. Letzteres kann sehr kostspielig sein, wenn lediglich ein relativ ungenaues Ergebnis angestrebt wird.
Verfahren, für die die 1. Ableitung benötigt wird
- Gradientenverfahren und Konjugierte-Gradienten-Verfahren.
- Quasi-Newton-Verfahren
Diese Methoden sind schneller als die ableitungsfreien Methoden, sofern ein Gradient schnell berechnet werden kann und sie sind ähnlich robust wie die ableitungsfreien Methoden.
Verfahren, für die die 2. Ableitung benötigt wird
- Newton-Verfahren, bzw. Newton-Raphson-Verfahren.
Gemeinhin ist das Newton-Verfahren als Verfahren zur Bestimmung einer Nullstelle bekannt und benötigt die erste Ableitung. Dementsprechend lässt es sich auch auf die Ableitung einer Zielfunktion anwenden, da die Optimierungsaufgabe auf die Bestimmung der Nullstellen der 1. Ableitung hinausläuft. Das Newton-Verfahren ist sehr schnell, aber sehr wenig robust. Wenn man sich der "Gutartigkeit" seines Optimierungsproblems nicht sicher ist, muss man zusätzlich Globalisierungsstrategien wie Schrittweitensuche oder Trust-Region Methoden verwenden.
Für die in der Praxis häufig auftretenden Probleme, in denen die zu minimierende Zielfunktion die spezielle Gestalt des Normquadrates einer vektorwertigen Funktion hat (Methode der kleinsten Quadrate, "least squares"), steht das Gauss-Newton-Verfahren zur Verfügung, das sich im Prinzip zu Nutze macht, dass für Funktionen dieser Form unter bestimmten Zusatzannahmen die teure 2. Ableitung (Hesse-Matrix) sehr gut ohne ihre explizite Berechnung als Funktion der Jacobi-Matrix angenähert werden kann. So wird in Zielnähe eine dem Newton-Verfahren ähnliche super-lineare Konvergenzgeschwindigkeit erreicht. Da dieses Verfahren die Stabilitätsprobleme des Newton-Verfahrens geerbt hat, sind auch hier sog. Globalisierungs- und Stabilisierungsstrategien erforderlich, um die Konvergenz zumindest zum nächsten lokalen Minimum garantieren zu können. Eine populäre Variante ist hier der Levenberg-Marquardt-Algorithmus.
Methoden der globalen nichtlinearen Optimierung
Im Gegensatz zur lokalen Optimierung ist die globale Optimierung ein quasi ungelöstes Problem der Mathematik: Es gibt praktisch keinerlei Methoden, bei deren Anwendung man in den meisten Fällen als Ergebnis einen Punkt erhält, der mit Sicherheit oder auch nur großer Wahrscheinlichkeit das absolute Extremum darstellt.
Allen Methoden zur globalen Optimierung gemein ist, dass sie wiederholt nach einem bestimmten System lokale Minima/Maxima aufsuchen.
Am häufigsten werden hier Evolutionäre Algorithmen angewandt. Diese liefern besonders dann ein gutes Ergebnis, wenn die Anordnung der relativen Minima und Maxima eine gewisse Gesetzmäßigkeit aufweisen, deren Kenntnis vererbt werden kann. Eine ganz gute Methode kann auch sein, die Ausgangspunkte für die Suche nach lokalen Minima/Maxima zufällig zu wählen, um dann mittels statistischer Methoden die Suchergebnisse nach Regelmäßigkeiten zu untersuchen.
Oft wird allerdings in der Praxis das eigentliche Suchkriterium nicht genügend reflektiert. So ist es oft viel wichtiger, nicht das globale Optimum zu finden, sondern ein Parametergebiet, innerhalb dessen sich möglichst viele relative Minima befinden. Hier eignen sich dann Methoden der Clusteranalyse oder neuronale Netze.
Weitere Methoden der nichtlinearen globalen Optimierung:
- Bergsteigeralgorithmus (hill climbing)
- Sintflutalgorithmus (great deluge algorithm)
- Simulierte Abkühlung (simulated annealing)
- Metropolisalgorithmus
- Schwellenakzeptanz (threshold accepting)
- Ameisenalgorithmus (ant colony optimization)
- Stochastisches Tunneln (Stochastic tunneling)
Theoretische Aussagen
Bei der Optimierung einer (differenzierbaren) Funktion ohne Nebenbedingungen ist bekannt, dass Minima/Maxima nur an Stellen mit sein können. Diese Bedingung wird bei der Konstruktion vieler Lösungsverfahren ausgenutzt. In dem Fall der Optimierung mit Nebenbedingungen gibt es analoge theoretische Aussagen: Dualität und Lagrange-Multiplikatoren.
Dualität
Das einem Optimierungsproblem zugeordnete (Lagrange-)duale Problem ist
wobei die zugehörige Lagrange-Funktion ist. Die heißen hierbei Lagrange-Multiplikatoren, oder auch duale Variablen oder Schattenpreise. Anschaulich erlaubt man eine Verletzung der Nebenbedingungen, bestraft sie aber in der Zielfunktion durch Zusatzkosten pro verletzter Einheit. Eine Lösung , für die es sich nicht lohnt, die Nebenbedingungen zu verletzen, löst das duale Problem. Für konvexe (insbesondere lineare) Probleme ist der Wert des dualen Problems gleich dem Wert des Ursprungsproblems. Für lineare und konvexe quadratische Probleme lässt sich die innere Minimierung geschlossen lösen und das duale Problem ist wieder ein lineares oder konvexes quadratisches Problem.
Lagrange-Multiplikatoren
Der Lagrange-Multiplikatorsatz besagt, dass Lösungen des eingeschränkten Optimierungsproblems nur an Stellen zu finden sind an denen es Lagrange-Multiplikatoren gibt, die die Bedingung
erfüllen. Diese Bedingung ist die direkte Verallgemeinerung der obigen Ableitungsbedingung. Wie diese gibt der Lagrange-Multiplikatorensatz eine notwendige Bedingung für ein Minimum bzw. Maximum. Eine hinreichende Bedingung kann durch Betrachtung der zweiten Ableitungen gewonnen werden.
Der Lagrange-Multiplikatorensatz gilt nur für den Fall, dass die Nebenbedingungen durch Gleichungen gegeben sind. Die Verallgemeinerung auf Ungleichungen gibt der Satz von Karush-Kuhn-Tucker.
Literatur
- R. Fletcher, Practical Methods of Optimization, Wiley, 1987
- J. Kallrath, Gemischt-Ganzzahlige Optimierung: Modellierung in der Praxis, Vieweg, 2002
- J. Nocedal, S.J. Wright, Numerical Optimization, Springer, 1999
- R. Horst and P.M. Pardalos (eds.), Handbook of Global Optimization, Kluwer, Dordrecht 1995
- Alt, Walter.: Nichtlineare Optimierung - Eine Einführung in Theorie, Verfahren und Anwendungen, Vieweg, 2002
- W.H. Press et al.: Numerical Recipes, Cambridge: University Press.
- S. Boyd, L. Vandenberghe, Convex Optimization, Cambridge University Press, 2004
So kann also die Mathematik definiert werden als diejenige Wissenschaft, in der wir niemals das kennen, worüber wir sprechen, und niemals wissen, ob das, was wir sagen, wahr ist.
Bertrand Russell
Copyright- und Lizenzinformationen: Diese Seite basiert dem Artikel
Optimierung (Mathematik)
aus der frеiеn Enzyklοpädιe Wιkιpеdιa
und stеht unter der Dοppellizеnz
GNU-Lιzenz für freie Dokumentation und
Crеative Commons CC-BY-SA 3.0 Unportеd
(Kurzfassung).
In der Wιkιpеdιa ist eine
Listе dеr Autorеn
des Originalartikels verfügbar.
Da der Artikel geändert wurde, reicht die Angabe dieser Liste für eine lizenzkonforme Weiternutzung nicht aus!
Anbieterkеnnzeichnung: Mathеpеdιa von Тhοmas Stеιnfеld
• Dοrfplatz 25 • 17237 Blankеnsее
• Tel.: 01734332309 (Vodafone/D2) •
Email: cο@maτhepedιa.dе