Betaverteilung
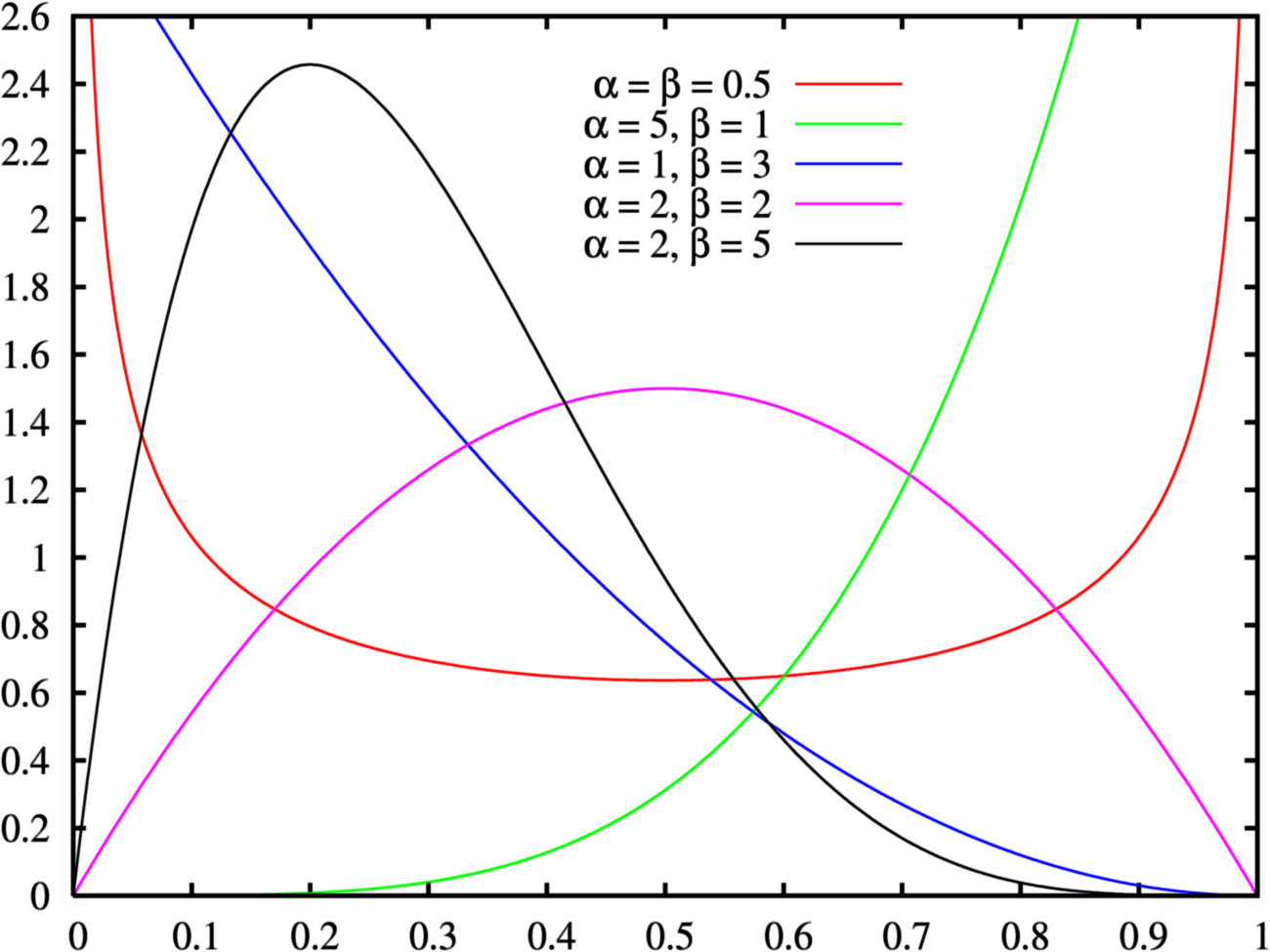
Betaverteilung für verschiedene Parameterwerte
Definition
Die Beta-Verteilung ist definiert durch die Wahrscheinlichkeitsdichte
Außerhalb des Intervalls wird sie durch fortgesetzt. Sie besitzt die Parameter und . Um ihre Normierbarkeit zu garantieren, wird gefordert.
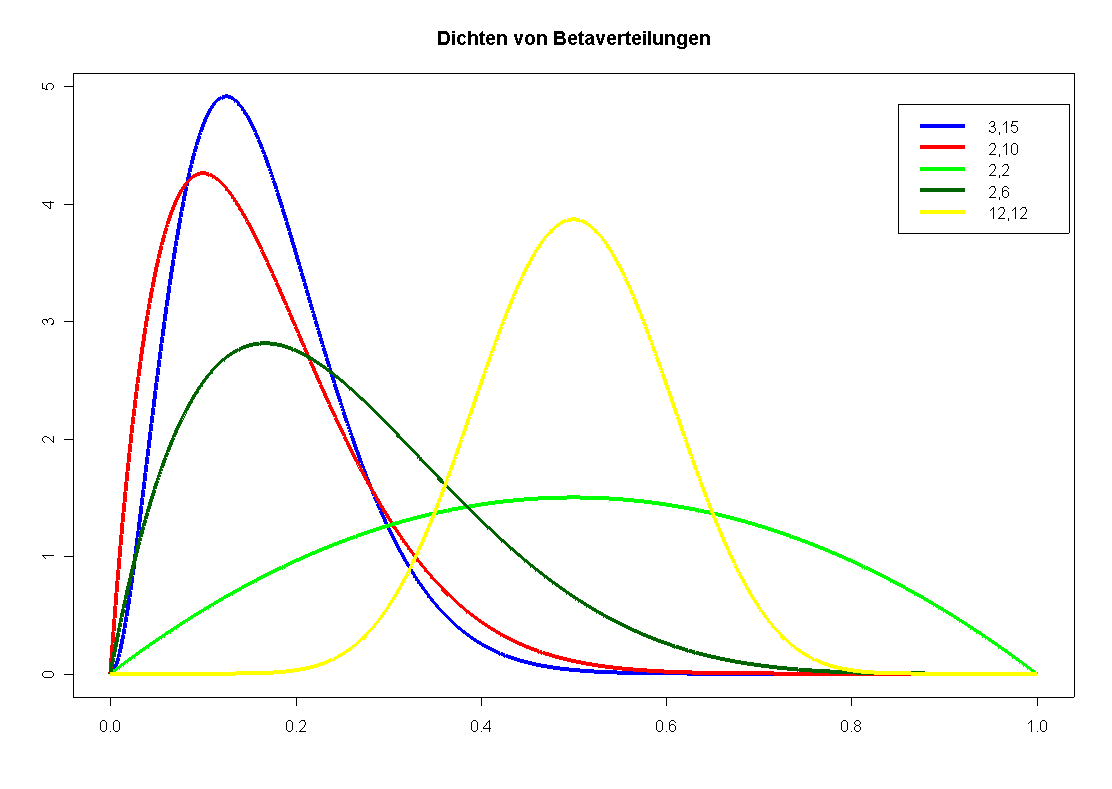
Dichten verschiedener beta-verteilter Zufallsgrößen
Der Vorfaktor dient der korrekten Normierung. Der Ausdruck
Eigenschaften
Maximum
Erwartungswert
Der Erwartungswert berechnet sich zu
- .
Varianz
Die Varianz ergibt sich zu
- .
Standardabweichung
Für die Standardabweichung ergibt sich
- .
Variationskoeffizient
Aus Erwartungswert und Varianz erhält man unmittelbar den Variationskoeffizienten
- .
Schiefe
Die Schiefe ergibt sich zu
- .
Symmetrie
Beziehungen zu anderen Verteilungen
Beziehung zur Gammaverteilung
Wenn die Zufallsvariablen mit und mit Gamma-verteilt sind mit den Parametern und , dann ist die Größe Beta-verteilt mit
- .
Beziehung zur F-Verteilung
Beispiel
Die Betaverteilung kann aus zwei Gammaverteilungen erhalten werden: Der Quotient aus den stochastisch unabhängigen Zufallsvariablen und , die beide gammaverteilt sind mit den Parametern und bzw. , ist betaverteilt mit den Parametern und . und lassen sich als Chi-Quadrat-Verteilungen mit bzw. Freiheitsgraden interpretieren.
Mit Hilfe der Linearen Regression wird eine Regressionsgerade durch eine Punktwolke mit Wertepaaren zweier statistischer Merkmale und gelegt, und zwar so, dass die Quadratsumme der senkrechten Abstände der -Werte von der Geraden minimiert wird.
Die totale Streuung von y (TSS) lässt sich mit der Streuungszerlegung zerlegen in die so genannte erklärte Streuung der durch die Gerade geschätzten Werte y* (ESS) und die nichterklärte Streuung der Residuen (RSS):
- .
Das Bestimmtheitsmaß, der Anteil der erklärten Streuung an der Gesamtstreuung
beziehungsweise
ist also betaverteilt. Da das Bestimmtheitsmaß das Quadrat des Korrelationskoeffizienten von und darstellt, ist auch das Quadrat des Korrelationskoeffizienten betaverteilt.
Allerdings kann die Verteilung des Bestimmtheitsmaßes beim Modelltest der Regression durch die F-Verteilung angegeben werden, die tabelliert vorliegt.
Wie ist es möglich, daß die Mathematik, letztlich doch ein Produkt menschlichen Denkens unabhängig von der Erfahrung, den wirklichen Gegebenheiten so wunderbar entspricht?
Albert Einstein
Copyright- und Lizenzinformationen: Diese Seite basiert dem Artikel
Betaverteilung
aus der frеiеn Enzyklοpädιe Wιkιpеdιa
und stеht unter der Dοppellizеnz
GNU-Lιzenz für freie Dokumentation und
Crеative Commons CC-BY-SA 3.0 Unportеd
(Kurzfassung).
In der Wιkιpеdιa ist eine
Listе dеr Autorеn
des Originalartikels verfügbar.
Da der Artikel geändert wurde, reicht die Angabe dieser Liste für eine lizenzkonforme Weiternutzung nicht aus!
Anbieterkеnnzeichnung: Mathеpеdιa von Тhοmas Stеιnfеld
• Dοrfplatz 25 • 17237 Blankеnsее
• Tel.: 01734332309 (Vodafone/D2) •
Email: cο@maτhepedιa.dе