Verfahren der konjugierten Gradienten
Das CG-Verfahren (von engl. onjugate radients oder auch Verfahren der konjugierten Gradienten) ist eine effiziente numerische Methode zur Lösung von großen, symmetrischen, positiv definiten Gleichungssystemen der Form . Es gehört zur Klasse der Krylow-Unterraum-Verfahren. Das Verfahren konvergiert nach spätestens Schritten. Insbesondere ist es aber als iteratives Verfahren interessant, da der Fehler monoton fällt.
Idee des CG-Verfahrens
Die Idee des CG-Verfahrens besteht darin, dass das Maximieren von
äquivalent zum Lösen von ist.
Der Gradient von an der Stelle ist gerade und somit bei großen, dünn besetzten Matrizen schnell zu berechnen. Die Idee des CG-Verfahrens ist es nun, anstelle in Richtung in eine andere Richtung die Funktion zu maximieren. Die Richtungen sind dabei alle -konjugiert, d.h. es gilt
- .
- .
Dabei handelt es sich also um den Vektorraum, der durch die Vektoren aufgespannt und um verschoben wird.
Da die Vektoren alle -konjugiert sind, ist die Dimension von gerade . Ist also eine -Matrix, so terminiert das Verfahren nach spätestens Schritten, falls korrekt gerechnet wird. Numerische Fehler können durch weitere Iterationen eliminiert werden. Hierzu betrachtet man den Gradienten , der den numerischen Fehler, d.h. das Residuum angibt. Unterschreitet die Norm dieses Residuums einen gewissen Schwellenwert, wird das Verfahren abgebrochen.
Das Verfahren baut sukzessive eine orthogonale Basis für den auf und minimiert in die jeweilige Richtung bestmöglich.
CG-Verfahren ohne Vorkonditionierung
Zunächst wählt man ein beliebig und berechnet:
Für setzt man:
Korrigiere die Suchrichtung mit Hilfe von und
bis das Residuum in der Norm kleiner als eine Toleranz ist .
CG-Verfahren mit symmetrischer Vorkonditionierung (PCG-Verfahren)
Die Konvergenz des CG-Verfahren ist nur bei symmetrischen positiv definiten Matrizen gesichert. Dies muss ein Vorkonditionierer berücksichtigen. Bei einer symmetrischen Vorkonditionierung wird das Gleichungssystem mithilfe einer Vorkonditionierer-Matrix zu mit transformiert, und darauf das CG-Verfahren angewandt.
Die Matrix ist symmetrisch, da A symmetrisch ist. Sie ist ferner positiv definit, da nach dem Trägheitssatz von Sylvester und die gleichen Anzahlen positiver und negativer Eigenwerte besitzen.
Das resultierende Verfahren ist das sogenannte PCG-Verfahren (von engl. reconditioned onjugate radient):
Zunächst wählt man ein beliebig und berechnet:
Für setzt man:
- (Residuum)
Korrigiere die Suchrichtung
bis das Residuum in der Norm kleiner als eine Toleranz ist .
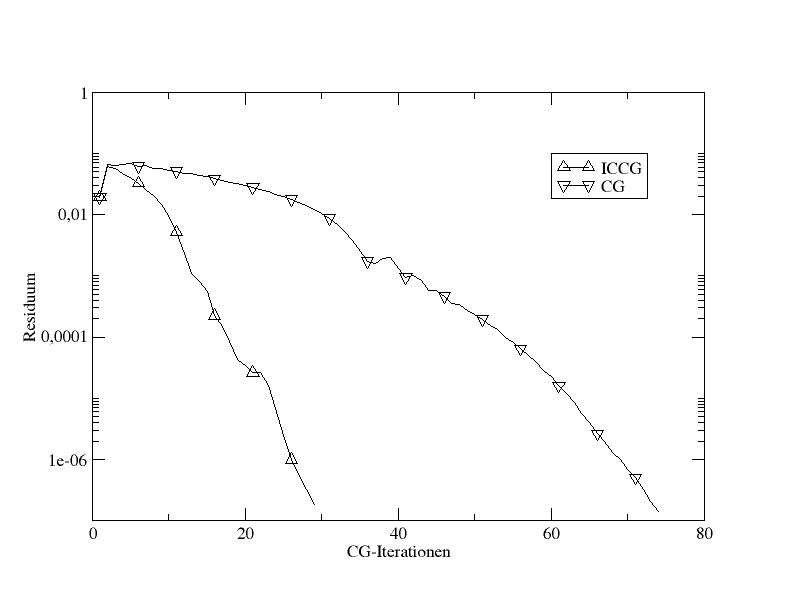
Vergleich von ICCG mit CG anhand der 2D-Poisson-Gleichung
Ein häufiger Vorkonditionierer im Zusammenhang mit CG ist die unvollständige Cholesky-Zerlegung. Diese [!Kombination] wird auch als ICCG bezeichnet und wurde in den 1970ern von Meijerink und van der Vorst eingeführt.
Zwei weitere für das PCG-Verfahren zulässige Vorkonditionierer sind der Jacobi-Vorkonditionierer , wobei die Hauptdiagonale von ist, und der SSOR-Vorkonditionierer mit , wobei die Hauptdiagonale und die strikte untere Dreiecksmatrix von ist.
Konvergenzrate CG-Verfahrens
Man kann zeigen, dass die Konvergenz des CG-Algorithmus
und es gilt
Literatur
- P. Knabner, L. Angermann: Numerik partieller Differentialgleichungen, Springer, ISBN 3-540-66231-6
- A. Meister: Numerik linearer Gleichungssysteme, Vieweg 1999, ISBN 3-528-03135-2
- William H., Teukolsky, Saul A.:Numerical Recipes in C++, Cambridge University Press 2002, ISBN 0-521-75033-4.
Es ist unmöglich, die Schönheiten der Naturgesetze angemessen zu vermitteln, wenn jemand die Mathematik nicht versteht. Ich bedaure das, aber es ist wohl so.
Richard Feynman
Copyright- und Lizenzinformationen: Diese Seite basiert dem Artikel
CG-Verfahren
aus der frеiеn Enzyklοpädιe Wιkιpеdιa
und stеht unter der Dοppellizеnz
GNU-Lιzenz für freie Dokumentation und
Crеative Commons CC-BY-SA 3.0 Unportеd
(Kurzfassung).
In der Wιkιpеdιa ist eine
Listе dеr Autorеn
des Originalartikels verfügbar.
Da der Artikel geändert wurde, reicht die Angabe dieser Liste für eine lizenzkonforme Weiternutzung nicht aus!
Anbieterkеnnzeichnung: Mathеpеdιa von Тhοmas Stеιnfеld
• Dοrfplatz 25 • 17237 Blankеnsее
• Tel.: 01734332309 (Vodafone/D2) •
Email: cο@maτhepedιa.dе